
Data Management Overview
On this page
The Curity Identity Server uses both permanent and temporary identity data. During user authentication and token issuance the system reads and writes user accounts and credentials. It also stores temporary data related to user sessions and tokens.
More generally, the Curity Identity Server separates concerns and allows you to use either a single data source or work with multiple data sources. This flexibility can help when you have requirements like integrating with existing identity infrastructure, meeting data sovereignty regulations across regions or partitioning users by tenant.
Data Storage Design
When planning deployments, design how to work with user accounts and credentials. User accounts in the Curity Identity Server follow the SCIM Core Schema. You can separate the storage of user accounts and user credentials, or integrate with existing data sources to read and write this information. Typically though, you need to deploy a new database for at least some identity data.
You can choose from many SQL or NoSQL Data Sources and should be able to use the same database technology for identity data that you use for APIs. Since the Curity Identity Server is cloud native, you can deploy its data sources anywhere, right next to your APIs. See the SQL and NoSQL tutorials to integrate your preferred storage.
Data Sources
The Curity Identity Server uses one or more Data Sources as an abstration that represents a backend system that provides data. The data source includes details like connection properties. You can use multiple data sources and compose them in your preferred ways. The following screenshot from the Admin UI shows the configuration for a PostgreSQL JDBC data source.
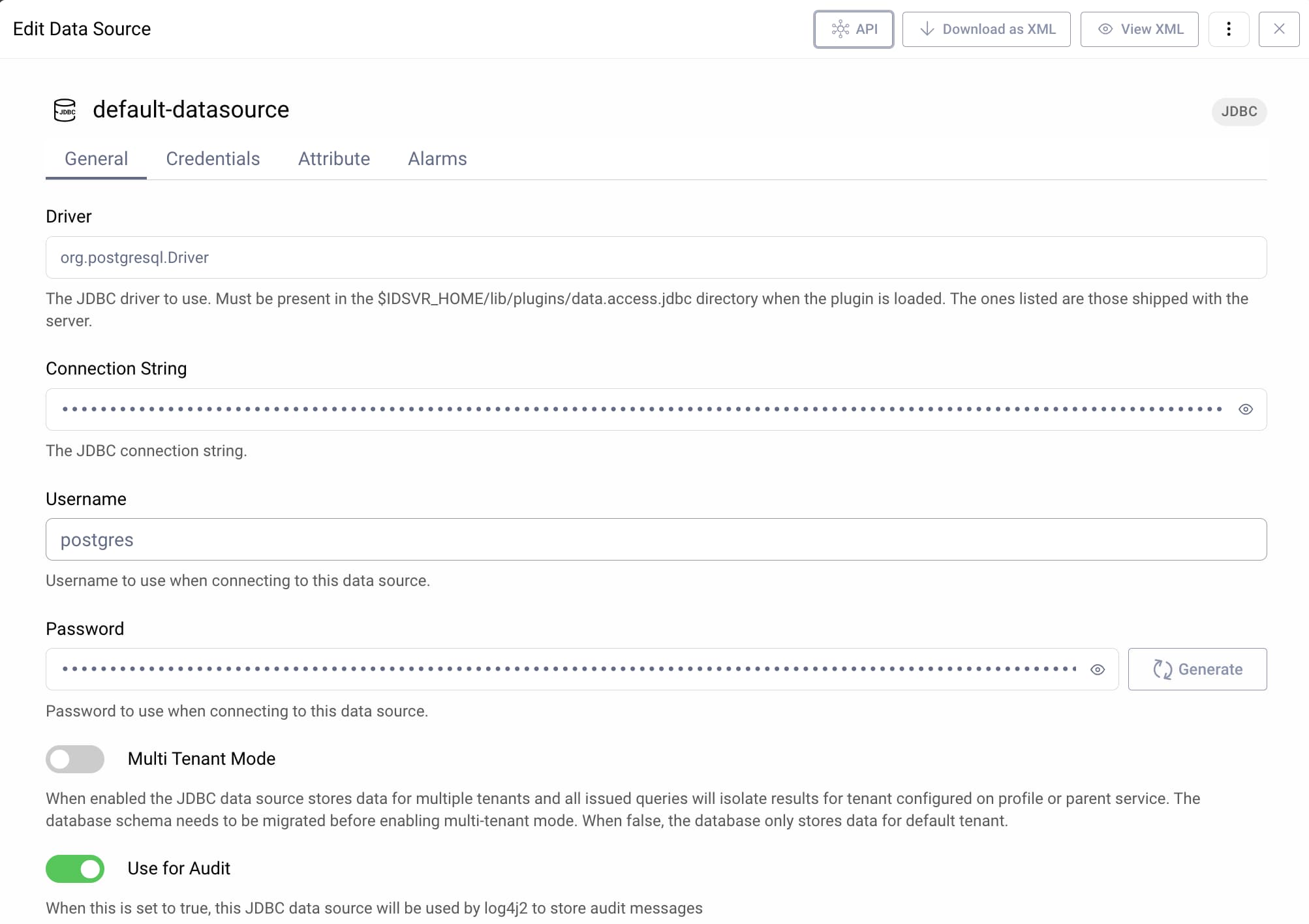
Each data source has a number of behaviors, summarized in the following table:
| Tab | Description |
|---|---|
| General | Sets technical connection details and other properties like whether to store multi-tenant and audit data. |
| Credentials | Sets credential storage preferences for data sources that store user credentials like passwords. |
| Attribute | Sets how to retrieve built-in or custom user attributes during user authentication and token issuance. |
| Alarms | Raises alarm events if the Curity Identity Server experiences problems connecting to the data source. |
Account Managers
The Curity Identity Server operates on user attributes from user accounts during user authentication and token issuance. To do so it uses an Account Manager abstraction that loads the attributes from a data source using Attribute settings from the data source. Some higher level services like the token service and authenticators reference an account manager to read and write user attributes.
Credential Managers
Credential managers operate on data sources to verify usernames and passwords. For that, they use the Credentials settings of the data source. In many cases, you can use the same data source for user accounts and user credentials. When you configure a credential manager, you choose a hashing algorithm for passwords and can configure a password policy with your preferred constraints. The following screenshot from the Admin UI shows the configuration for a credential manager.
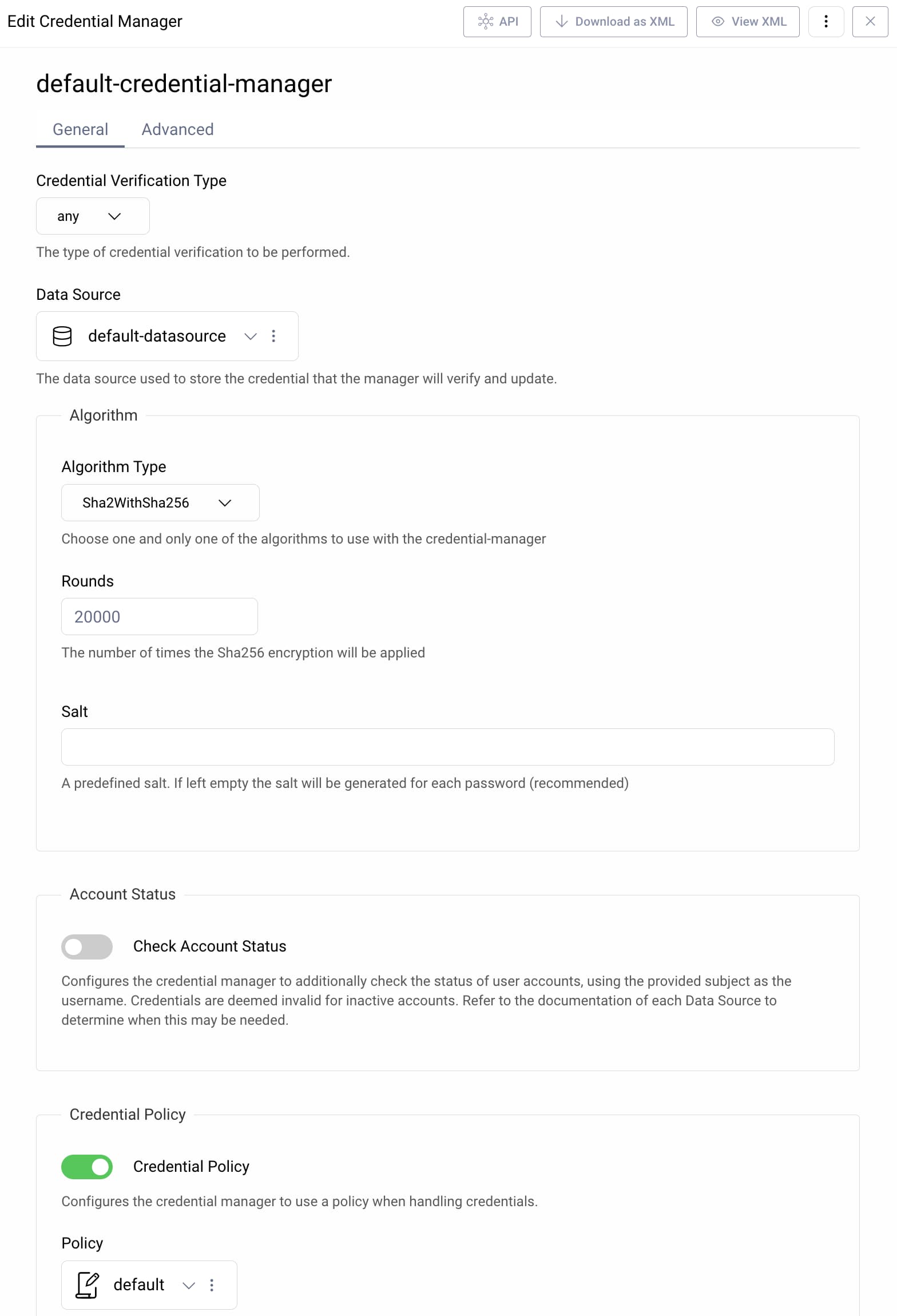
Credential managers can play an important role to enable migration from legacy identity infrastructure. A credential manager can connect to an existing data source, for example that uses LDAP or SCIM. In some deployments you can configure credential rehashing to more secure formats without requiring password resets for users. Read more about credential managers in the Product Documentation.
Custom Data Sources
If you need to integrate with user accounts and credentials stored in a custom data source like a legacy database, use the Curity Identity Server's SDK to develop a Data Access Plugin. For example, implement UserAccountDataAccessProvider and CredentialManagementDataAccessProvider objects in a REST API that connects to the custom data source. Deploy the plugin with the Curity Identity Server and configure it as an extra data source.
API Access to Identity Data
When you use OAuth you typically store some user data, such as personally identifiable information (PII), in the authorization server, which can help to meet User Privacy requirements. By default, applications receive user information in tokens or from the OpenID Connect userinfo endpoint.
When required, applications can also connect to SCIM and GraphQL APIs that operate on user accounts and user credentials stored in data sources. To use these APIs you configure an Authorization Manager to control which clients and users can access which user information.
Multi-Region Data
You can operate more complex deployments of the Curity Identity Server, that span multiple regions. To do so, deploy the same configuration settings to all regions but use separate database instances. The Multi-Region Deployment article explains some ways to provide OAuth URLs and manage regional identity data.
To help with regional database management, you can configure a Service Role with a zone attribute to represent a region. You can then use a Multi-Zone Data Source so that the Curity Identity Server uses the correct regional data source.
When planning multi-region identity data storage, also consider possible data sovereignty restrictions on where you store some types of user information. In such cases, consider the use of Dynamic User Routing to reliably route user requests to their home region based on a region claim issued to access tokens.
Multi-Tenancy
In other types of deployment you might need to partition users by tenant. For example, you might provide B2B2C applications or store user accounts from business partners. The Curity Identity Server allows you to design multi-tenant deployments in your preferred ways, depending on your particular requirements for data isolation.
The tutorial on Running the Curity Identity Server in a Multi-Tenant Architecture explains the design choices for both OAuth endpoints and data storage. Although you can use fully isolated data sources and Profiles per tenant, that may not be the easiest to manage deployment.
A more cost-effective option can be for some or all tenants to share the same tenant-aware database. For example, you could create an authentication profile for each tenant and assign it a tenant ID. When users get created during authenticated flows, those user accounts get assigned the profile's tenant ID. You can then easily issue the tenant ID in the user account as a custom claim to access tokens.
Summary
The Curity Identity Server supports many ways to manage identity data for user accounts and user credentials. Follow the Getting Started with Identity Data tutorial to get up and running. Aim to use the same data access technologies for both the Curity Identity Server and your APIs. Later, meet deeper requirements by composing multiple data sources. When required, develop plugins to extend default beheviors, so that you are never blocked.

Join our Newsletter
Get the latest on identity management, API Security and authentication straight to your inbox.

Start Free Trial
Try the Curity Identity Server for Free. Get up and running in 10 minutes.
Start Free TrialWas this helpful?