Multi-Region Deployment
On this page
Intro
When companies decide on a hosting strategy for their software platform, they must account for several high-level factors:
- Countries in which the software will be used
- Ensuring adequate performance and scalability across regions
- Ensuring that the software is highly available and can recover from failures
- Region-specific restrictions related to systems and data
This article will describe how to deploy the Curity Identity Server across multiple datacenters and regions. The options chosen depend upon the specific problems the company is trying to solve.
Hosting Big Picture
Hosting in an OAuth architecture typically requires three main types of HTTPS endpoint called by apps: Web Content, APIs, and the Authorization Server. The company will also design URLs and domain names to provide these endpoints:

For the system to be highly available and perform well, the components then need to be scaled. Also, the data used by the APIs and Authorization Server needs to be managed reliably overtime to meet regulatory requirements.
Identity Server Deployments
A basic form of production hosting is to ensure at least two instances of each component type, except for data sources, which are frequently backed up. This could be hosted on-premise, although it is more common these days to deploy to the cloud, often using containers and Kubernetes.
For the Curity Identity Server, the components are illustrated below. We recommend driving the deployment from configuration:
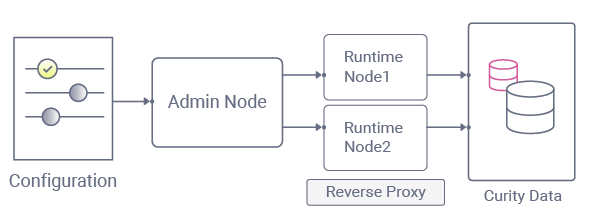
| Component | Behavior |
|---|---|
| Configuration | Configuration is provided as part of the startup image and then updated via the Admin UI or REST API. |
| Admin Node | The admin node is responsible for receiving configuration and then feeding updates to runtime nodes. |
| Runtime Nodes | Runtime nodes serve your applications and also listen for any configuration changes from the admin node. |
| Data Sources | When runtime nodes handle authentication and token requests, they connect to data sources. |
The admin node should not be exposed to the internet. This is usually managed via network segmentation. The end result is that the admin node is only available when authorized company employees are connected to their work network.
Runtime nodes are independent and never call each other, meaning that they remain in a working state even if they cannot connect to the admin node. This provides a simple deployment design that scales well to any type of global cluster.
Internet Entry Points
For any systems that deal with data sources, it is recommended to host the actual nodes behind a reverse proxy rather than exposing the nodes directly to the internet.
| Component | Entry Point |
|---|---|
| Curity Identity Server | The entry point for the Curity Identity Server can be a simple reverse proxy, such as a Kubernetes Ingress. |
| APIs | The entry point for APIs is typically a gateway, such as those provided by cloud systems, with the capability to introspect access tokens. |
| Web Back Ends | If a web back end stores data-related secrets, such as database connection strings, a reverse proxy should be used here as well. |
| Web Static Content | It is common to use a Cloud Content Delivery Network (CDN) to deliver static web content that contains no sensitive information. |
Single Region
Therefore, a company hosting within a single region would require only a fairly simple Identity Server deployment, where internet apps send OAuth requests via the reverse proxy's public URL.

It is common to use built-in support from cloud-native platforms such as Kubernetes to manage nodes as production conditions change. The below areas can then run without manual human actions to help ensure the system's availability:
- Auto repair faulty nodes when a node no longer passes health checks.
- Autoscale nodes when the system is under a high user load.
- Use an Infrastructure-as-Code (IaC) approach to automate the deployment.
The Curity Identity Server provides the following Monitoring Capabilities that can be called by the cloud platform:
| Capability | Description |
|---|---|
| Health | Status endpoint on port 4465 can be used to determine basic availability and see if an instance is healthy. If not, the cloud platform can be configured to mark the instance down and spin up a new node to replace it. |
| Metrics | Metrics endpoints on port 4466 can be used to report details on how many requests or how much CPU / memory a node is using. Rules can be configured in the monitoring system to adjust the number of nodes based on results. |
| Alarms | If the nodes themselves are healthy but experience a problem connecting to another resource, then Alarms can be used to enable immediate alerts that point to the failing component. |
Active Passive
Although the above infrastructure has some great reliability, it may not cope with certain events, such as a hurricane that brings down electrical power for an entire region.
If your company needs to guarantee that the software keeps working under these conditions, a typical pattern is to failover to a different region.

This is reasonably easy to achieve with a cloud platform since you would use scripting such as Terraform to automate deployment to both locations. You would then need to keep the configuration data up to date in the passive location when it changes in the active location:
| Operation | Description |
|---|---|
| Initial Deployment | The latest XML configuration is included as part of the deployment so that nodes never 'start blank.' This is typically done by embedding configuration in the Docker image or supplying it as a parameter to the Kubernetes Helm chart. |
| Configuration Updates | Changes to the configuration in the active location can be managed via an Identity Server event that invokes a webhook, perhaps to save data to a Git repository. A job in the passive location can then pull this data and apply it to the passive admin node via its REST API. |
Global Cluster
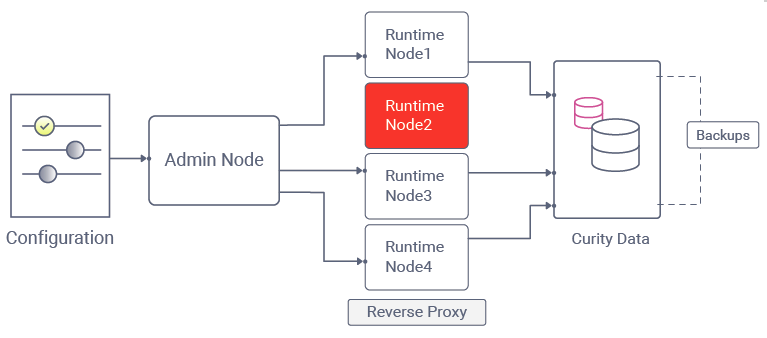
When using a single-region deployment, the overall system is likely to be considerably slower for users in remote countries. Companies targeting a global user base will likely want performance to be roughly equal for all users, so they may decide to extend their hosting to three or so locations.
One hosting strategy is to use Global Server Load Balancing (GSLB), where end users are routed to the geographically closest endpoints. This type of load balancing is usually also accompanied by data replication so that all regions eventually end up with the same data.
To include the Curity Identity Server in this type of global deployment, its components should be deployed as illustrated below.

Data Sovereignty and Localization
We recommend that companies store Personally Identifiable Information (PII) about end users in the Curity Identity Server, as described in the Privacy and GDPR Article.
However, replicating this type of data could break newer laws in some regions, where companies can only store personal data on servers within the user's country.
Data and Regulations
Companies must carefully consider regulatory aspects before replicating sensitive data across legal boundaries. In these cases, a solution based on Global Subclusters or Dynamic User Routing may be preferred.
In the following sections, we will assume there are no such legal barriers and describe how to reliably cluster the Curity Identity Server across regions.
Data in the Curity Identity Server
Architecturally, we separate data into these main types:
| Data Type | Description |
|---|---|
| Tokens and Authenticated Sessions | This data should always be stored in a database in a clustered setup, enabling the Identity Server to correctly handle OAuth requests from applications, to perform authentication, token issuing, token refresh, and logout. |
| User Accounts and Credentials | This data can either be stored in the same database, or the Identity Server can interact with an external source, such as a Custom Database, Custom API, or LDAP storage. |
| Logs | Audit information is usually routed to the database, whereas system logs for troubleshooting are instead stored in text files that can be aggregated to a central log store. No PII data is included in logs when using the recommended production log level of INFO. |
Companies running a clustered setup will need a database for at least the first of these, and can use either a SQL or NoSQL schema. Database and LDAP software used in a global cluster must support active-active replication, ensuring eventual consistency. Replication times for databases are typically fast, such as a few seconds, whereas global LDAP replication may take several minutes.
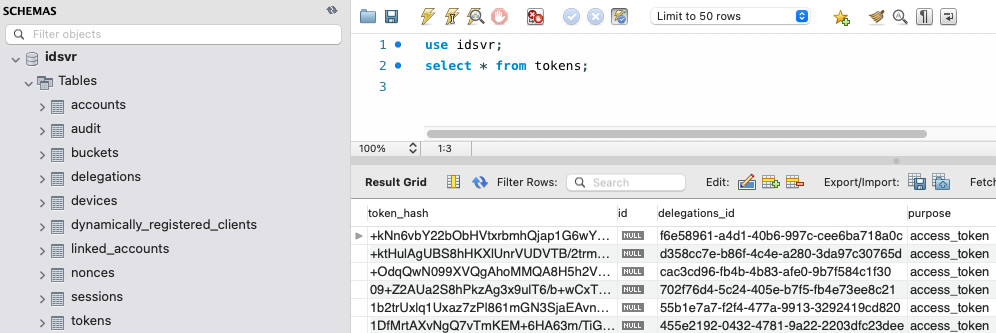
The below table provides further information on particular areas of data within the above schema:
| Data Type | Description |
|---|---|
| User Credentials | If a company wants to store accounts in the database, and use password credentials, then the default behavior is to store hashed credentials in the accounts table. |
| User Account Data | Other user account data can be stored in the database alongside credentials, including the user's name and email, both of which are typically used for password recovery emails. Companies using the Curity Identity Server must decide how much Personally Identifiable Information (PII) to store against users. |
| Access Tokens | Access tokens are used as API message credentials, and the data is backed by database storage that can be replicated. |
| Refresh Tokens | Data to enable the silent renewal of access tokens is also backed by database storage that can be replicated. |
| SSO Cookie | After user authentication, a cookie is issued by the Curity Identity Server, which any global node can decrypt, and which links to a delegation in the database. This cookie is used to achieve Single Sign-On across multiple apps and can also be used to refresh tokens in Single Page Applications via prompt=none requests. |
| Temporary Sessions | Some authenticators use temporary cookies during redirects to external systems, and these cookies are self-contained. This data does not need to be replicated across regions. |
Load Balancing Reliability
Users will be routed to the geographically closest Curity Identity Server node, but occasionally they may be routed to another region, which could happen for various infrastructure-related reasons. Companies will want to ensure that this does not lead to a poor user experience for their end-users, and we recommend testing the following scenarios in your setup.
| Scenario | Description |
|---|---|
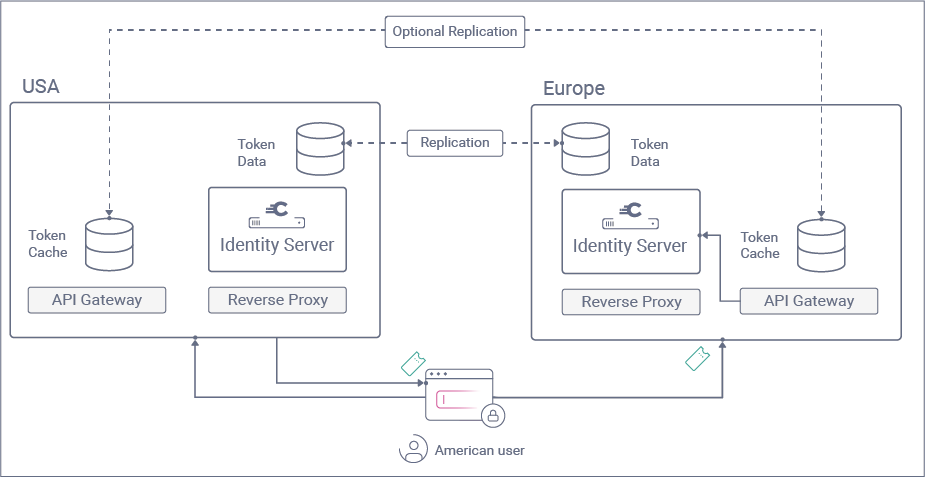
| User Logins | If an American user is routed to Europe servers, then the user's credential should exist, and the user should be able to login into the new region. |
| Authenticated Session Operations | If an American user is routed to Europe servers shortly after signing in, the user should not be asked to sign in again since this provides poor usability. Instead, the issued OAuth tokens should be replicated to the new region. As a result, access token introspection, token refresh, and logout will all work to ensure a reliable user experience. |
API Gateway Data
The API Gateway used with the Phantom Token Pattern also contains data, most commonly an access token cache, where it is common to store a hash of recently received access tokens.
If users get routed to a different region, tokens can be used normally in the new region. This is because the gateway will just re-introspect the token, which will succeed due to replicated token data.
Some advanced API gateways have their own features for synchronizing data across gateway nodes, and some companies may want to enable the following type of behavior:
- The ability to replicate token caches across regions, which can be useful with the Split Token Pattern
- The ability to listen for Identity Server Events such as logout, then removing all cached tokens for that user
Reliable Use of Access Tokens
We recommend coding OAuth client applications to handle 401 error responses from APIs in the standard manner: refreshing the token and then retrying the API request. This can help to ensure a good user experience in some infrastructure scenarios.
An example is illustrated below, where the Split Token Pattern is used, with a gateway that does not support token cache replication. The user has been authenticated in one region and is then redirected to another region.

| Step | Description |
|---|---|
| 1. Token sent from Client to API Gateway | The client application sends an opaque access token in the form of a JWT signature. The token was issued in another region, where the gateway cache contains the corresponding signature hash and JWT payload. |
| 2. Token rejected by API Gateway | The API Gateway in the new region does not contain the signature hash in its cache, so it rejects the token. |
| 3. 401 response error received by Client | The client application receives an API response with HTTP status 401, even though its token is valid and not expired. |
| 4. Token Refresh request sent | The client application sends a refresh token, or, if it is a Single Page Application, it could send a prompt=none redirect. |
| 5. New Token sent to Gateway | The API gateway in the new region receives details for the new token and adds them to its cache. |
| 6. New Token returned to Client | The client application then receives a new opaque access token valid for the new region. |
| 7. New Token sent from Client to API Gateway | The client application then sends the new token to the gateway, which will be accepted. |
The end result is that the application has resiliently coped with re-routing via simple and standard code. The switch is seamless for the end-user, who does not experience any technical problems or additional browser redirects.
Global Sub Clusters
The Data Sovereignty and Localization topic mentioned earlier adds extra challenges for software companies who are trying to provide global software solutions:
- Some governments may insist that personal data belonging to software users cannot be sent outside the user's country.
- Some governments may block cloud providers who are not deemed to be aligned with that country's rules and regulations.
To resolve these problems, data will need to be partitioned rather than replicated, and one option is to use region-specific internet URLs:
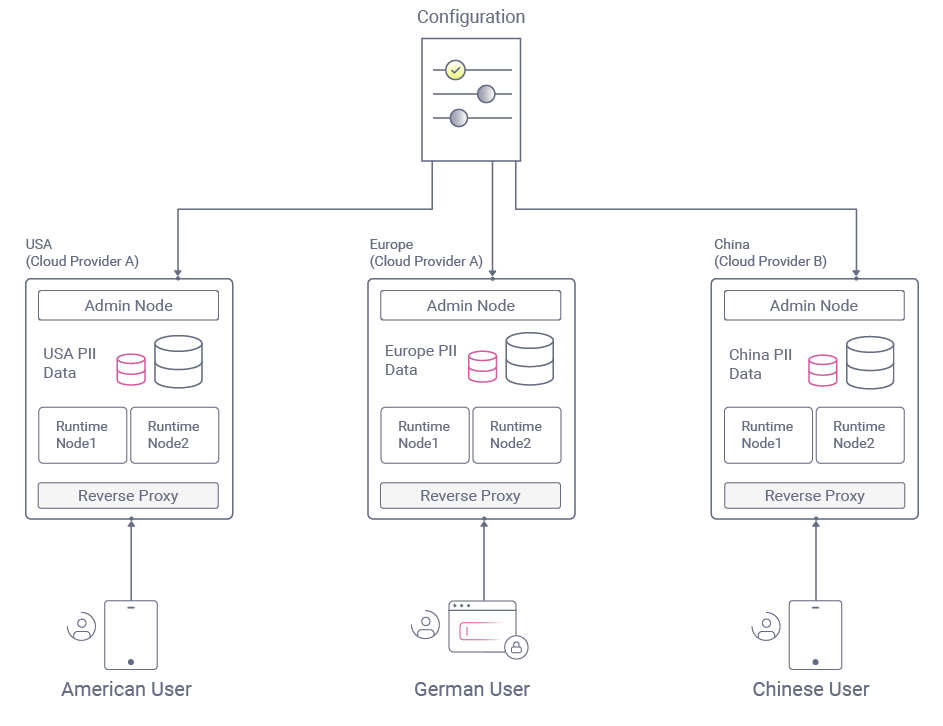
Global deployment may also require a multi-cloud capability, where some countries require a different cloud provider. The Curity Identity Server is designed to be provider-agnostic and deployable to any cloud. Once you are up and running in one location, extending your deployment automation to other providers is straightforward.
Dynamic User Routing
It is possible to take closer control of a global deployment via reverse proxy routing. This enables you to run a single global system, with user data partitioned by region but without the need for data replication. Instead, users are always routed to instances of the Curity Identity Server running in their home region.
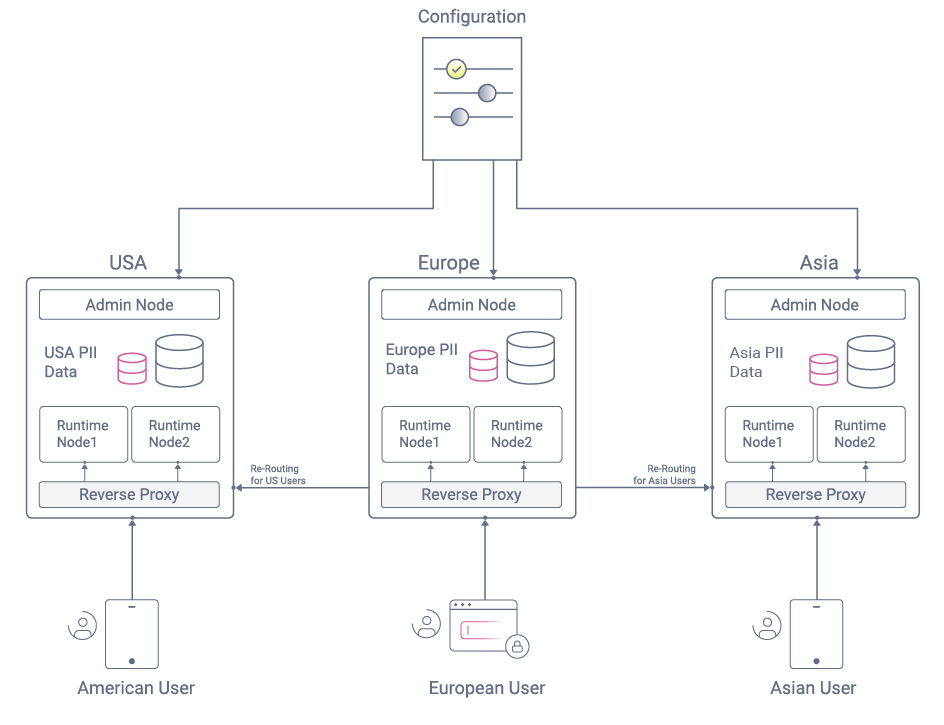
For further details on this design pattern, see the following articles:
Conclusion
The Curity Identity Server can be deployed to any platform, then clustered to meet your global software needs. This enables companies to achieve their software hosting goals:
- High availability
- Globally equal performance
- Expanding to new regions
- Keeping user data private


Gary Archer
Product Marketing Engineer at Curity
Customer Stories
Learn how organizations run identity and API security at scale.
Read customer storiesWas this helpful?