

Transaction Tokens: The New Phantom Tokens?


Software environments are constantly evolving. Changes to architectures, technologies, and company structures affect the threats our systems face. It is common nowadays to break down systems into smaller components that can handle concrete features. Sometimes this means adopting a microservice approach. But even if the system operates as a monolith, it will often rely on other components that it connects with via APIs. This means that nearly every request a backend system processes these days will eventually travel through a few services.
The popularity of componentized architectures has led security experts to develop solutions that allow processing requests more securely and adhere to zero-trust principles. The IETF’s OAuth working group has proposed a solution as a new standard: transaction tokens. A transaction token is a security credential that complements the usage of access tokens to provide stronger security. In this post, I will explain in more detail what transaction tokens are and the reasons for using them. I will also compare the technology to a pattern that we’ve advocated at Curity for almost a decade now — the phantom token pattern.
Why Do You Need Transaction Tokens?
In an architecture where one request traverses multiple services and components, it becomes important to view security from a zero-trust perspective and not rely solely on perimeter security. In a perimeter security approach, requests inside the infrastructure have implicit trust, which can lead to vulnerabilities.
Once the token is validated at the perimeter, the internal traffic uses implicit trust.
In this setup, if any of the services or components become compromised, then an attacker gains unlimited access to all elements of the system and can inflict a lot of damage to the company’s business. A component can become compromised in various ways:
A service uses an insecure implementation in its code that allows an external attacker to take control of the service, also known as remote code execution (RCE).
A service uses dependencies that become the target of a supply-chain attack, and an external attacker manages to breach a service despite correct security measures implemented in code.
An external attacker manages to break into the company’s virtual internal network using vulnerabilities in a public cloud used by the company.
A rogue employee operates from inside the company to steal the company’s data.
Companies can implement two types of security measures to create a zero-trust environment: infrastructure-level security and application-level security.
With infrastructure-level security, you lock down which services can talk to each other. If one service becomes breached, then the attacker can only call a limited number of services in the infrastructure. This limits the amount of data they can steal, but it does not offer complete protection. For example, an order-processing service might have access to a service that holds information about users’ addresses or credit cards. If the order service is compromised, the attacker can steal the sensitive data by querying the credit card service. This is where application-level security comes in.
With application-level security, you lock down the caller so that they can only operate on a limited set of data. This is where you use solutions like access tokens to authorize a request — for instance, a user can only request their own credit cards and addresses when placing an order.
Using a zero-trust approach also means that every service in the call chain independently authorizes the request using the incoming access token. If an attacker manages to breach the order service now, they won’t be able to steal any data from the credit card service, as they would also need to steal an access token that allows them to query the credit card service.
Even though the system now uses access tokens to limit access, the token might have too many privileges, which can still lead to data loss. If an attacker manages to get hold of an access token, they might still be able to perform attacks on the systems:
If the attacker manages to steal access tokens from the breached service, they can reuse them to call the company’s APIs to steal more data.
If the attacker manages to get an access token out-of-band, they can use it from the breached service to call other services, as access tokens have no information about the context in which the token is used — the services don’t know if the token is used as part of a legitimate request, or if it is used to perform an attack.
Transaction tokens try to address the above issues.
How Do Transaction Tokens Work?
When a system uses transaction tokens, it swaps an access token for the transaction token to be used for the duration of a given request.
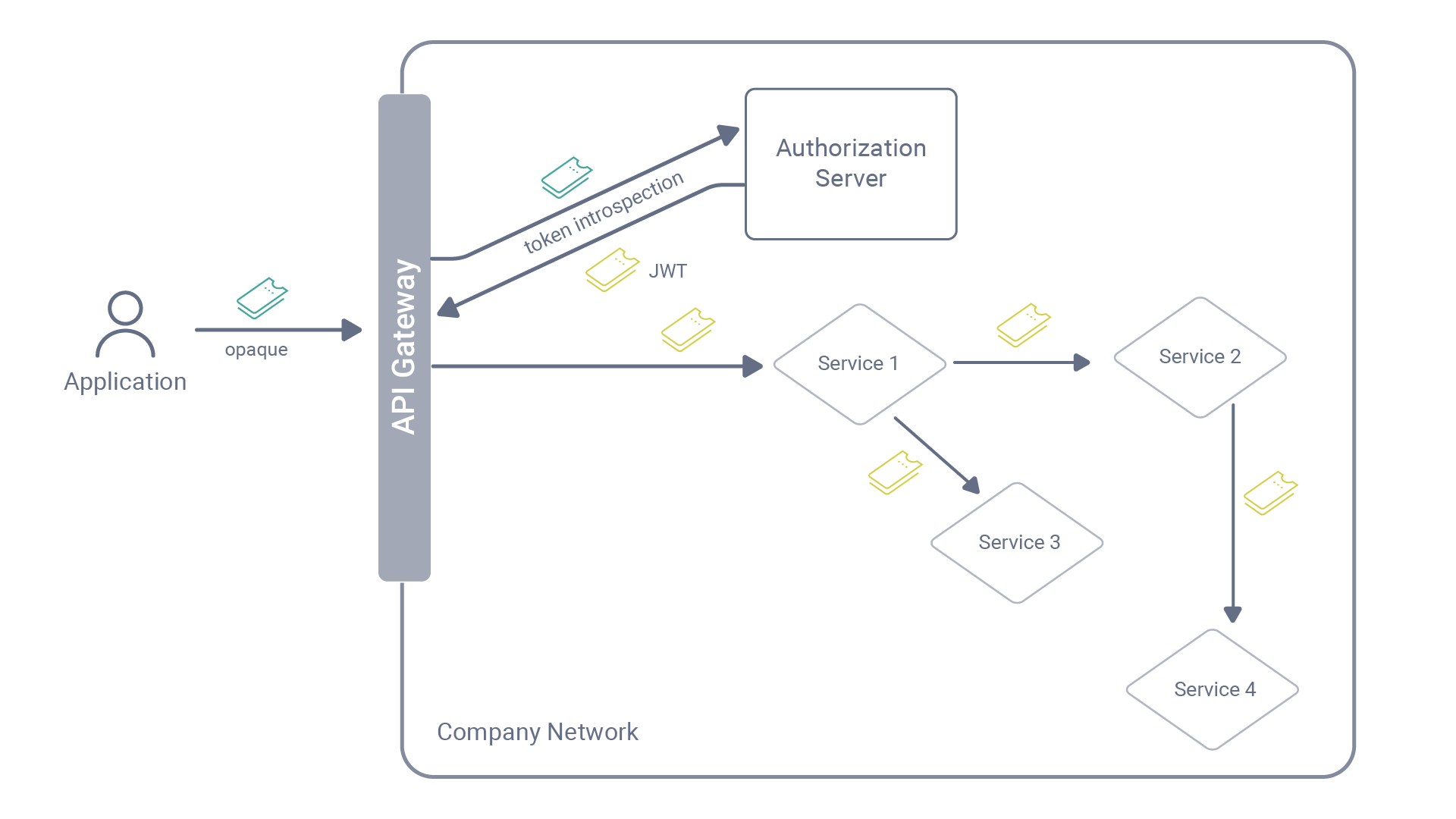
A request that uses transaction tokens.
When the system starts processing an incoming request, it first exchanges the incoming access token for a transaction token. This should happen early in the process, so an API gateway will usually be the place that performs the exchange. The API gateway will send the access token to the token service (the authorization server if the system uses OAuth) and receive a specially prepared JSON Web Token (JWT) that should contain:
Relevant information associated with the access token that services might need for authorization, like the subject ID or the subject’s roles.
A unique ID of the current request (transaction) that can be used to correlate information about the request and prevent token replay.
Information about the request’s context, like the endpoint called and the HTTP method used, or the requester’s IP address.
The gateway then passes down the transaction token in a Txn-Token HTTP header, so it is not confused with an access token. A receiving service can then verify the context of the request and properly authorize the token subject. If an attacker manages to intercept such a token, they will not be able to use it at external-facing API endpoints (as this is not an access token recognized by the API gateway). They also will not be able to use it outside the token’s context, like calling other internal services with the token. The attacker will have only a limited time to try to abuse the token, as transaction tokens should have a lifespan limited to the request’s expected processing time.
Additionally, the specification enables services to replace transaction tokens and update them with new context information. This also allows a service to verify that a proper call chain was adhered to for the concrete transaction. For example, a payment processing service could accept a transaction token only if the context contained information that a fraud prevention service previously handled the request.
The Phantom Token Pattern
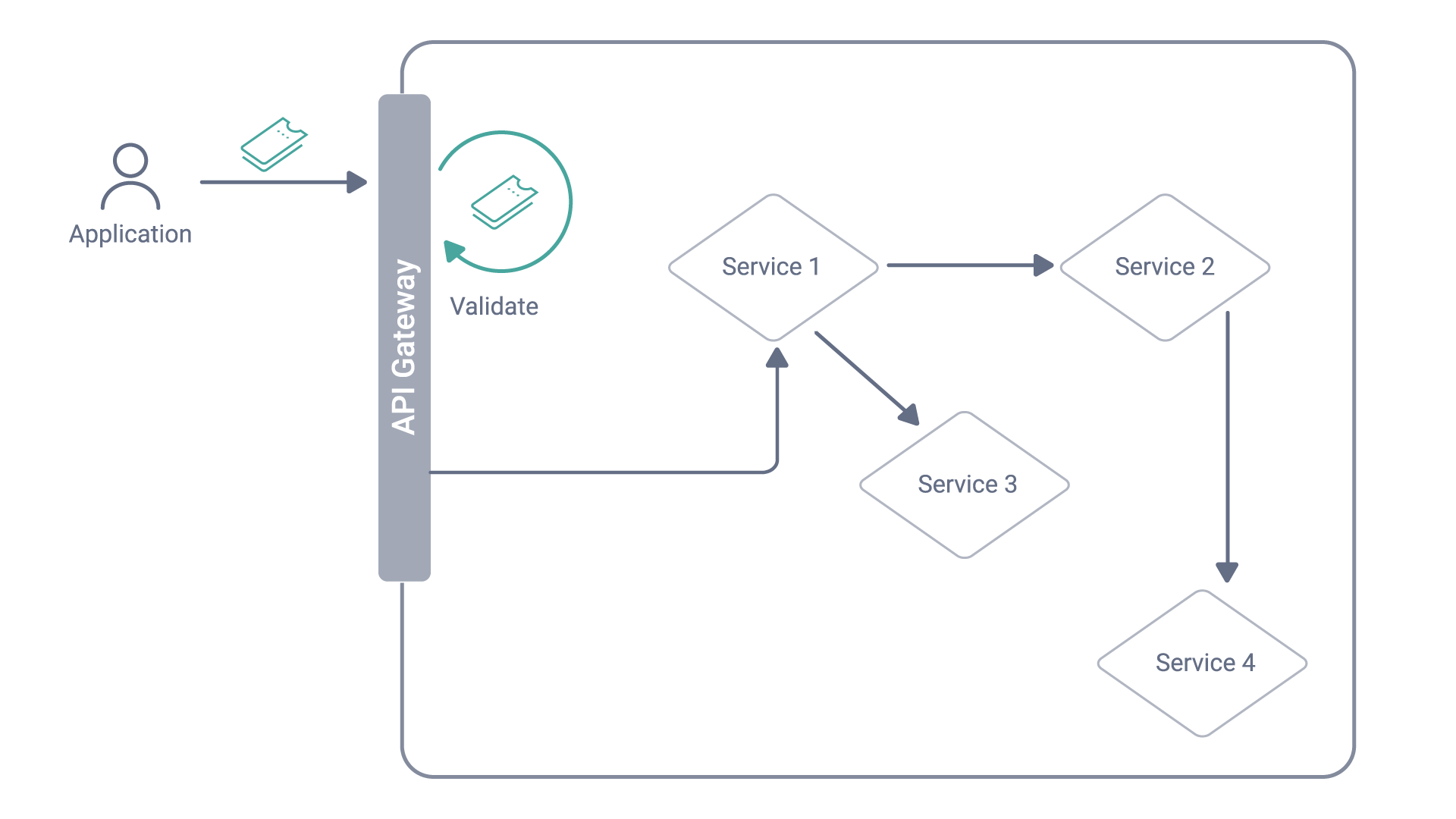
At Curity, we’ve been recommending using the phantom token pattern to protect the access token from some abuses. When using the pattern, the token service always issues an opaque token to clients (applications). Then, when an API gateway receives the opaque token, it performs token introspection and gets a JWT with all the information corresponding to the opaque token. The gateway then uses the JWT as the access token when passing the request down to internal services.
A request that uses the phantom token approach.
The JWT representation of the access token can only be used by internal services, hence the phantom token name — the original application would not be able to use it, and in fact, never knows of the existence of such a token. Internal services can conveniently use the token to authorize requests, but it can’t be replayed against public API endpoints, as it doesn’t match the original access token.
The phantom token pattern solves some of the issues that transaction tokens tackle, but there are also some differences between the two approaches.
The Similarities Between Transaction and Phantom Tokens
Let’s start with what the two approaches have in common. Both transaction tokens and phantom tokens use JWTs as a secure and convenient format for credentials. Services can easily verify the integrity of a JWT, and the token carries all the required information so that services can process it offline — this cuts down the amount of traffic between services processing requests and the token service.
Both solutions require that systems use different tokens inside and outside their infrastructure. This protects from the threat of an attacker stealing access tokens on an internal network and then reusing them at public-facing APIs. This is the main threat that both solutions help to tackle.
How Are Transaction and Phantom Tokens Different?
The phantom token approach expects the token service to issue opaque tokens to external clients. This allows protecting the token’s content. With an opaque token, no party handling the token can read its associated data. This means that the token can be safely associated with sensitive or personal information that internal services need for authorization purposes. The transaction tokens specification only describes how internal tokens are created and used, and does not impose any format on external tokens.
Transaction tokens are locked down to one concrete transaction or request, and they can include information about the request’s context. Phantom tokens do not contain this information. The introspected JWT is valid for the duration of the original access token’s lifespan, and every introspection request should yield the same JWT — the introspection response is cacheable. This also means that phantom tokens can’t carry information about the current call chain, something that transaction tokens can be used for.
The two approaches use different standards:
Phantom tokens utilize a variant of the introspection specification,
Transaction tokens are implemented using the token exchange specification.
This means the token service must support different solutions to implement these approaches. The implementation also varies on the services’ side, even though both approaches use JWTs. Phantom tokens are forwarded in the Authorization HTTP header, meaning services can work with standard libraries that handle authorization and JWT validation. Transaction tokens, on the other hand, are forwarded in a proprietary header, which requires bespoke authorization implementation, because there are still no libraries that support the standard.
How to Implement Transaction and Phantom Tokens
The two solutions are complementary, and you might consider implementing them both. However you decide to create the implementation, you should always fulfill some crucial requirements:
Always use opaque tokens when sending tokens outside your infrastructure.
Never use the same token outside and inside your infrastructure.
Once inside your infrastructure, enrich the token with additional information that can further limit its usage (like the request context).
Fulfilling the above requirements will usually mean following these steps:
Ensure that your token service (like the authorization server if you are using OAuth) issues an opaque token to clients that operate outside your infrastructure, like mobile apps or web apps.
Have your API gateway introspect or exchange the opaque token for a JWT. Then use the JWT among services when processing the request.
Enrich tokens with additional information when performing an exchange, so that the token contains information about the request context.
You will be left with an architectural decision, depending on the concrete requirements of your setup. You can either implement the transaction token standard (thus ensure proper JWT formatting and use headers required by the specification) or forward tokens in the usual Authorization header to simplify integration with your existing services.
Conclusion
Phantom tokens and transaction tokens are two approaches that help you solve concrete issues of a distributed system. While they both protect against internal token theft, they also have features that complement each other, so you might consider implementing both (or creating implementations that will take their best parts). For now, implementing the phantom token approach should be less intrusive, as it relies on a standard way for token validation in services. As the Transaction Tokens specification is in a draft state, the implementation details might still change. However, once it is published as an RFC, it will facilitate interoperability, and the industry will probably publish libraries for handling transaction tokens.